
Diabetes Prediction App
A Machine Learning based project deployed on Heroku and developed with Python and streamlit library. Supervised Machine Learning Classification problem, solved using Ensemble Learning technique. Algorithms used here are Logistic Regresssion and Random Forest Classification with a model test accuracy of more than 94%
Ensemble Learning
An ensemble-based system is obtained by combining diverse models (mainly classifiers). Therefore, such systems are also known as multiple classifier systems, or just ensemble systems. There are several scenarios where using an ensemble based system makes statistical sense. We use such an approach routinely in our daily lives by asking the opinions of several experts before making a decision. For example, we typically ask the opinions of several doctors before agreeing to a medical procedure, we read user reviews before purchasing an item , we evaluate future employees by checking their references, etc. In each case, a final decision is made by combining the individual decisions of several experts. In doing so, the primary goal is to minimize the unfortunate selection of an unnecessary medical procedure, a poor product, an unqualified employee or even a poorly written and misguiding article. Same is the case with Machine Learning models. One model may fail learn some records and other models may find it easy to learn. So in many cases Ensemble Learning can be a better option.
Logistic Regression
Logistic Regression is a Classification problem based on Supervised Machine Learning. Logistic regression models the probabilities for classification problems with two possible outcomes. It’s an extension of the linear regression model for classification problems. The problem for Linear Regression in classification is that it predicts a range of values or continuous values, like as price prediction. But in classification only binary values are used that is either cat or dog, either suffering from diabetes or not. For this, in Logistic Regression we apply a sigmoid function.
logistic(η) = 1 / 1+exp(−η)
This sigmoid function converts all values from - infinity to infinity in range 0 to 1. Then a threshold values is applied and values are compressed to binary format.
Random Forest
Random forests is a supervised learning algorithm. It can be used both for classification and regression. It is also the most flexible and easy to use algorithm. A forest is comprised of trees. It technically is an ensemble method of decision trees generated on a randomly split dataset. This collection of decision tree classifiers is also known as the forest. The individual decision trees are generated using an attribute selection indicator such as information gain, gain ratio, and Gini index for each attribute. Each tree depends on an independent random sample. In a classification problem, each tree votes and the most popular class is chosen as the final result. In the case of regression, the average of all the tree outputs is considered as the final result. It is simpler and more powerful compared to the other non-linear classification algorithms.
Prediction
| Not Diabetic | Diabetic |
|---|---|
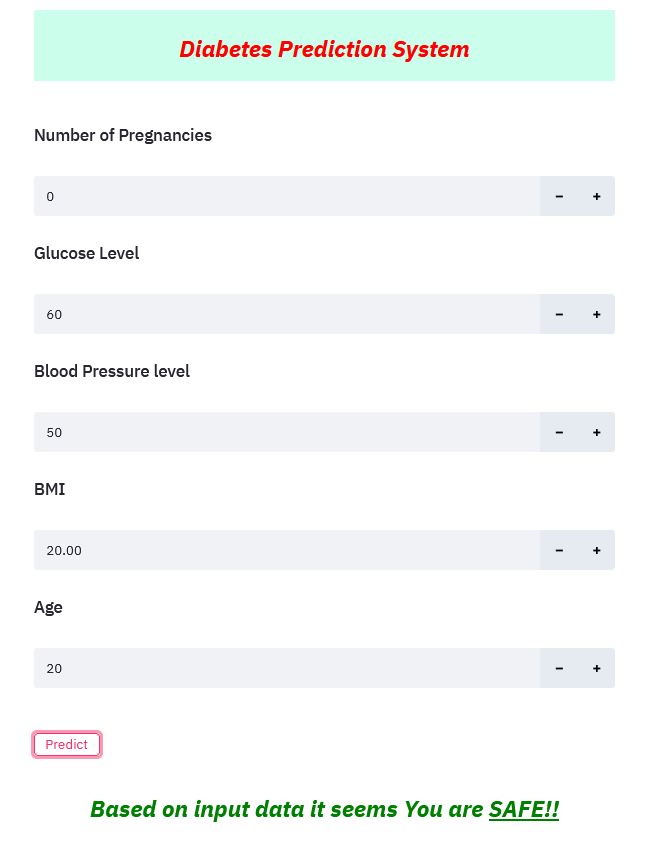 |
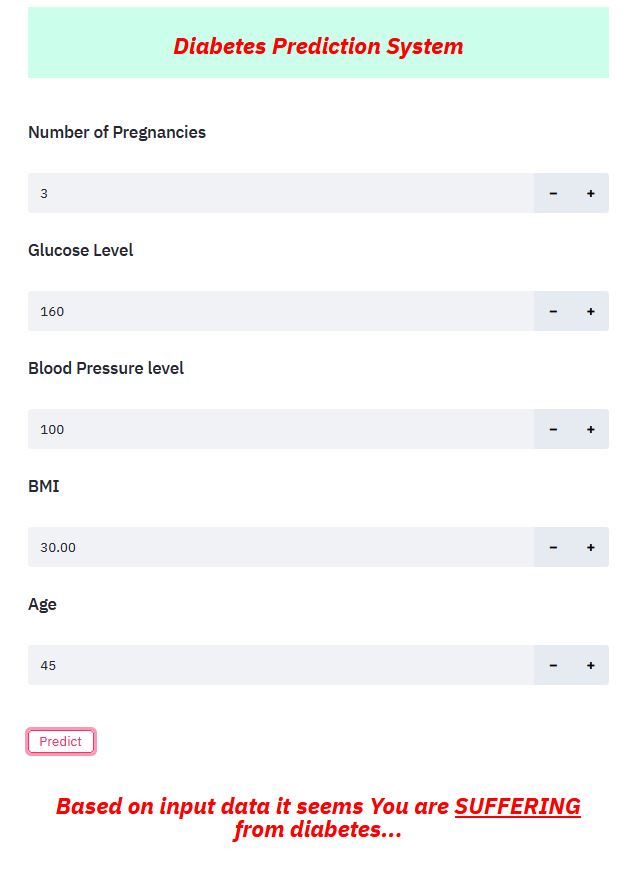 |